Airbnb is a globally recognized short-term rental and experience platform. By using web scraping techniques, it is possible to automatically collect data from listing pages and uncover market insights that are not directly provided by the platform. However, compared with ordinary websites, Airbnb is significantly more difficult to scrape.
This article takes a practical, implementation-oriented approach and explains how to build an Airbnb scraper using Python. The goal is to help you efficiently collect Airbnb listing data while maintaining stability throughout the scraping process.
I. What Types of AI Training Require Airbnb Data?
With the rapid development of AI travel assistants and travel technology, high-quality real-world short-term rental data has become a critical resource for training intelligent agents and multi-scenario AI models. Airbnb data can be applied in the following three areas.
- Intelligent travel assistants and personalized itinerary generation
By collecting Airbnb pricing, availability, and listing information, AI systems can learn to generate personalized travel plans based on user preferences, predict seasonal price fluctuations, estimate total trip budgets including accommodation, attractions, dining, and transportation, optimize dynamic pricing recommendations, and adjust itineraries in real time by updating routes and budgets.
Applicable scenarios include intelligent travel assistants, AI tour guides, personalized itinerary generation agents, travel planning SaaS products, travel recommendation applications, and AI travel budget assistants.
- Travel property and market forecasting AI
When combined with data from other platforms, Airbnb data can be used for market trend forecasting such as identifying popular cities, regions, property types, and occupancy rate changes. It can also support investment analysis by predicting short-term rental returns and revenue volatility, as well as identifying cities or regions with development potential for short-term rentals.
Applicable scenarios include property investment analysis tools, short-term rental revenue management systems, city tourism planning and business analysis, and data-driven market research platforms.
- Travel content generation and creative AI (AIGC)
Real listing and attraction data can be used to train AI models for content generation, including automatic creation of travel guides, travel journals, and short-form video scripts. AI can also generate titles, copy, and recommendation reasons to support content platforms and short-video operations. Multimodal generation combining images, text, and video can significantly improve content creation efficiency.
Applicable scenarios include AI-powered travel content platforms, travel-focused short video and media operations, and personalized travel recommendation systems.
II. Key Challenges in Scraping Airbnb
Scraping Airbnb is far more complex than sending a few HTTP requests, as the platform has implemented extensive data protection mechanisms.
- Strong anti-scraping systems
Airbnb pages rely heavily on JavaScript rendering, and much of the core content only appears after browser-side execution. The platform detects automated requests through behavior analysis, IP sources, and access frequency. Common blocking methods include IP restrictions and CAPTCHA challenges.
- Frequent page structure changes
HTML structures, class names, and internal interfaces are frequently adjusted. Without continuous maintenance, existing scrapers can easily break.
- IP access limitations
Even when requests succeed, Airbnb limits the number of requests per IP within a given time window. Poor strategies often result in incomplete data or blocked IPs.
III. Common Approaches and Tools for Airbnb Web Scraping
There are two main approaches to scraping Airbnb data: using third-party data APIs or building a custom scraper. This article focuses on building a Python-based scraper. For users with basic programming skills, a self-built scraper offers full control over data collection logic and scope.
Commonly used tools include Playwright or Selenium for real browser rendering, handling JavaScript-heavy content, and simulating user behavior, as well as BeautifulSoup for parsing rendered HTML and extracting titles, prices, and ratings.
With continuous tracking of Airbnb page changes, this type of scraper can scale from small research projects to long-term stable data collection workflows. While more labor-intensive than off-the-shelf tools, it offers flexibility, control, and customization.
IV. Practical Workflow: Scraping Airbnb Listings in Three Steps
Below, we build a Playwright-based Airbnb scraper that supports automatic pagination and basic anti-detection strategies to improve stability.
- Pre-run preparation
Before starting, several preparations are required.
First, install Python and Playwright. Python 3.7 or higher is recommended. Playwright requires downloading browser engines such as Chromium, Firefox, or WebKit.
Second, use built-in modules. The script relies mainly on Python built-in modules such as csv, time, and re, without requiring additional installations.
Third, configure a residential proxy. Airbnb is highly sensitive to access frequency and IP sources. Using a residential proxy can significantly reduce blocking risk. A commonly used option is IPFoxy’s rotating residential proxy, which automatically rotates IPs at high frequency to bypass anti-scraping mechanisms. IPFoxy provides a pool of over 70 million real residential proxy IPs with a purity rate of up to 99.8 percent, global traffic mixing technology that allows a single request to use IPs from multiple countries, and compatibility with Python, PHP, Java, Golang, and other mainstream programming languages.
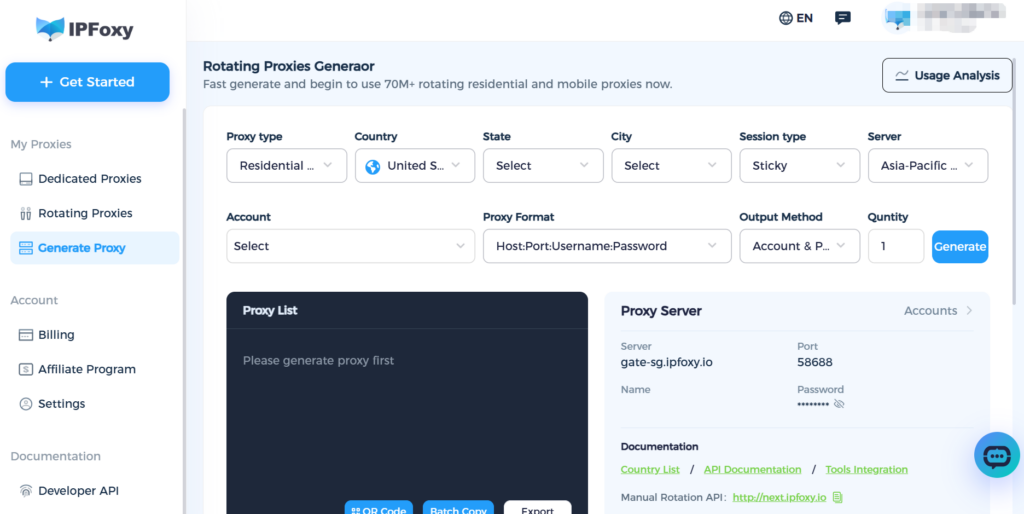
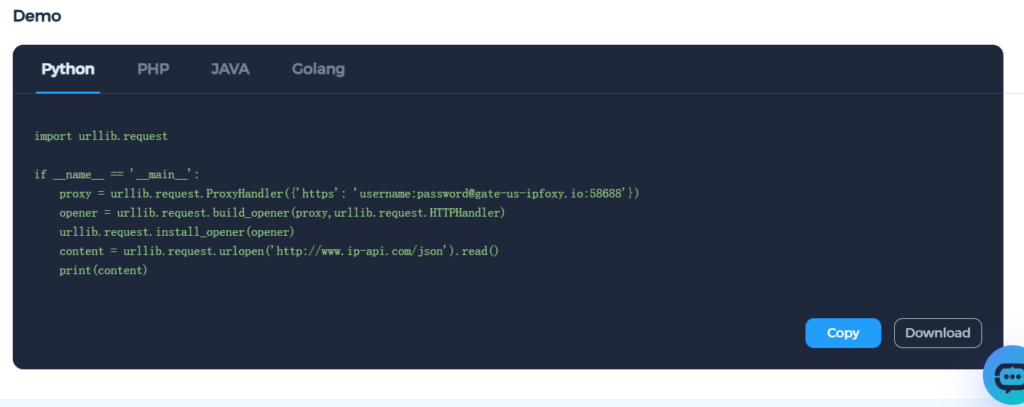
- Identifying and locating Airbnb page data structures
Before writing the scraper, it is essential to understand how data is rendered and stored in the browser.
First, inspect the rendered HTML. Open an Airbnb search results page in Chrome or Firefox, right-click anywhere on the page, select Inspect, and use the element selector to click a listing card. Each listing is wrapped in a structurally similar container, which can be treated as the root node for a single listing.
Second, identify the locations of core listing data. Within the listing container, key data includes the title or short description, typically distributed across multiple child elements and extracted as text; ratings and review counts, often displayed in formats like 4.95 (123) and extracted using regular expressions; price information, usually located within specific class elements and requiring precise CSS selectors; and listing detail links, which are found in anchor tags whose href attributes contain the /rooms/ path.
Third, use Playwright to locate and extract data. In the scraper, Playwright’s locator system is used to target the listing container as the base selector. Within each container, the scraper extracts title and description text, ratings and review counts through regex parsing, price fields, and listing URLs. To prevent duplicate collection, a room ID is extracted from the listing URL and used as a unique identifier.
- Scraper structure design
The scraper is designed using an object-oriented approach, centered around a core class called AirbnbScraper for easier maintenance and extension.
The extract_listing_data method receives a single listing container element and parses the title, description, rating, review count, and price. Numeric fields are extracted using regular expressions. If critical information is missing, the method returns None to prevent invalid data from entering the results.
The pagination logic is implemented in the scrape_airbnb method. It automatically scrolls to the bottom of the page or pagination area, locates the next-page button, and controls the maximum number of pages based on a configurable parameter.
To reduce detection risk, several anti-detection strategies are applied. These include running Chromium in headless mode with stealth parameters, injecting JavaScript to hide webdriver characteristics, setting randomized realistic User-Agent strings, adding random delays to simulate real browsing behavior, and automatically handling cookie consent pop-ups.
After scraping is complete, the results are saved as a well-structured CSV file for further analysis and processing. The save_to_csv method exports key fields such as listing title, description, rating, review count, price, and listing URL, while excluding internal listing IDs used only for deduplication to ensure clean and usable data.
After saving, the main program prints a preview of the scraped results in the terminal to quickly verify that the data has been correctly captured.
Conclusion
This article presents a complete and practical approach to scraping Airbnb listing data, covering page structure analysis, Playwright-based rendering, basic anti-detection strategies, and structured data storage. With appropriate tools and scraping strategies, it is possible to obtain structured listing data in a stable and scalable manner. The solution is highly extensible and suitable for long-term price monitoring, market trend analysis, and more advanced data research scenarios.

