Reddit is one of the most visited forum communities in the world, covering nearly every vertical from technology and finance to beauty and gaming. The authentic emotional expression and in-depth discussions from Reddit users provide highly valuable insights for sentiment monitoring, market research, and AI model training.
However, despite the high value of Reddit data, reliably collecting it is not easy. Many developers and operators encounter issues such as request limits, blocked IPs, and incomplete responses when attempting to scrape Reddit. These challenges become even more significant when running large-scale or long-term data collection tasks, as Reddit’s anti-scraping mechanisms increase the difficulty.
Through this guide, you can build a stable and scalable Reddit data scraping solution from scratch.
I. What is Reddit Data Scraping?
Reddit data scraping refers to using automated programs (web crawlers) to collect publicly available data from Reddit in bulk.
This data includes rich unstructured content such as:
● Post titles and content
● Comments and nested replies
● Engagement metrics such as upvotes and followers
● Subreddit names and tags
● Posting time and basic user information
● External URLs and media attachments
Using crawlers, this scattered and unstructured information can be cleaned and transformed into structured, storable, and analyzable datasets. These datasets can then be used for competitor research, sentiment analysis, or automated product development.

II. Why Does Reddit Data Scraping Often Fail?
Many developers experience scraping failures not due to a single technical issue, but because of Reddit’s combined risk control mechanisms, data structure, and access policies.
1. Rate Limiting
When a crawler sends a large number of requests in a short time, Reddit detects abnormal traffic and triggers restrictions. If limits are exceeded, the source IP may be temporarily blocked or throttled, resulting in empty responses, 403 errors, or 429 Too Many Requests.
2. Strict IP Risk Control
This is one of the most common and critical reasons for scraping failures. Reddit places high requirements on IP authenticity and stability. Even when using a proxy pool, low-quality proxies or improper rotation strategies can still trigger restrictions.
For example:
Data center IPs are easily identified as automated traffic
Shared proxies often have high contamination levels
Frequently reused proxies are more likely to be restricted
3. User-Agent and Fingerprint Detection
Reddit checks HTTP headers and access characteristics to determine whether requests originate from real users. If the User-Agent shows crawler identifiers or lacks common browser headers, requests may be flagged as abnormal.
Under stricter detection, Reddit may also analyze:
Request intervals
Access behavior
Browser fingerprints
These factors further increase the probability of blocking.
4. Strict API Access Limits
Although Reddit provides official APIs, free access quotas continue to shrink. API rate limits and restricted data scopes often become bottlenecks in large-scale scraping scenarios, potentially causing task interruptions or incomplete datasets.
5. Frontend Dynamic Rendering
Reddit’s modern frontend uses frameworks such as React. Most page content is dynamically loaded through JavaScript rather than returned directly in HTML.
This means traditional HTTP tools such as Python requests often only retrieve basic page structure instead of full post and comment data. To obtain complete content, developers usually need to simulate browser behavior or analyze internal API calls, increasing technical complexity and maintenance costs.
6. Login Wall and Permission Restrictions
Some Reddit content now requires login access. Scraping without authentication may result in incomplete data. Using multiple accounts for scraping introduces additional risks, including account restrictions, bans, and account association issues. This can lead to both account and IP restrictions simultaneously.
To scrape Reddit reliably, you must handle anti-scraping mechanisms, especially rate limits and IP blocking. Combining Python with rotating proxy is one of the most effective solutions.
III. How to Scrape Reddit Data Reliably
Python provides powerful HTTP libraries. When combined with rotating proxy, it can effectively avoid many of the issues mentioned above. For example, IPFoxy Proxies rotating proxy hides your real IP and rotates addresses for each request, making scraping behavior appear as if it originates from different users and reducing block risks.
1. Configure Rotating Proxy in Python
We will use Python requests and IPFoxy Proxies for configuration.
Step 1: Install Required Library
pip install requestsStep 2: Configure Rotating Proxy
When scraping Reddit, high request frequency or flagged IPs can easily trigger restrictions. Configuring rotating residential proxy helps reduce block risks and keeps crawlers stable.
Below is an example using IPFoxy Proxies rotating residential proxy.
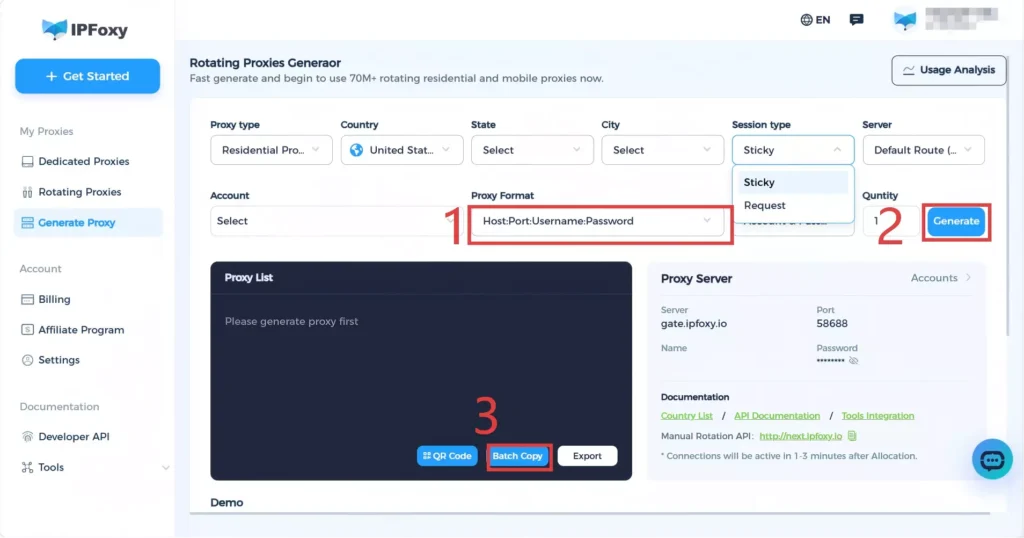
1. Obtain Proxy Information
Get rotating residential proxy from IPFoxy Proxies and configure:
State and city
Protocol type
Session rotation type
Proxy format
Then obtain the proxy connection details.
2. Configure Proxy in Python
Paste the proxy credentials into the following example:
import urllib.request
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)Once executed, you will see the exit IP change, indicating successful configuration.

Step 3: Reddit Python Scraping Example
Below is a complete example using requests and IPFoxy rotating proxy:
import requests
import time
import random
# ============================================================
# IPFoxy Proxy Configuration — Replace with your actual credentials
# ============================================================
IPFOXY_USERNAME = "your_ipfoxy_username"
IPFOXY_PASSWORD = "your_ipfoxy_password"
IPFOXY_PROXY_HOST = "gate.ipfoxy.com"
IPFOXY_PROXY_PORT = "10000"
# ============================================================
# Target URL (Use .json endpoint to return structured data directly, no HTML parsing needed)
# Modify r/popular to the subreddit you want to scrape
# ============================================================
TARGET_SUBREDDIT = "popular"
TARGET_URL = f"https://www.reddit.com/r/{TARGET_SUBREDDIT}.json"
# Maximum posts per request (Reddit supports up to 100)
LIMIT = 25
# Number of scraping rounds
ROUNDS = 3
def get_proxies():
"""Build IPFoxy dynamic proxy configuration"""
proxy_url = (
f"http://{IPFOXY_USERNAME}:{IPFOXY_PASSWORD}"
f"@{IPFOXY_PROXY_HOST}:{IPFOXY_PROXY_PORT}"
)
return {"http": proxy_url, "https": proxy_url}
def get_headers():
"""Return a randomized browser-like request header"""
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
]
return {
"User-Agent": random.choice(user_agents),
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": "https://www.reddit.com/",
}
def fetch_reddit_json(url, params=None):
"""
Request Reddit JSON endpoint via dynamic proxy.
Returns parsed dict, or None on failure.
"""
proxies = get_proxies()
headers = get_headers()
try:
response = requests.get(
url,
headers=headers,
proxies=proxies,
params=params,
timeout=15,
)
response.raise_for_status()
return response.json()
except requests.exceptions.ProxyError as e:
print(f" [Proxy Error] Proxy connection failed. Check credentials or proxy address: {e}")
except requests.exceptions.Timeout:
print(" [Timeout] Request timed out. Current proxy response is too slow")
except requests.exceptions.HTTPError as e:
print(f" [HTTP Error] Status code {e.response.status_code}, possibly rate-limited or blocked")
except requests.exceptions.RequestException as e:
print(f" [Request Exception] {e}")
except ValueError:
print(" [Parse Error] Response is not valid JSON. Possibly triggered CAPTCHA or redirect")
return None
def parse_posts(data):
"""Extract post list from Reddit JSON response"""
posts = []
try:
children = data["data"]["children"]
for item in children:
post = item["data"]
posts.append({
"title": post.get("title", ""),
"subreddit": post.get("subreddit_name_prefixed", ""),
"score": post.get("score", 0),
"comments": post.get("num_comments", 0),
"url": "https://www.reddit.com" + post.get("permalink", ""),
"author": post.get("author", ""),
"created_utc": post.get("created_utc", 0),
})
except (KeyError, TypeError) as e:
print(f" [Parse Error] Data structure exception: {e}")
return posts
def main():
print(f"Start scraping r/{TARGET_SUBREDDIT}, total {ROUNDS} rounds\n")
all_posts = []
after = None # Reddit pagination cursor
for i in range(ROUNDS):
print(f"--- Round {i + 1} ---")
params = {"limit": LIMIT}
if after:
params["after"] = after # Pagination: pass cursor from previous page
data = fetch_reddit_json(TARGET_URL, params=params)
if data is None:
print(" Failed this round, skipping\n")
time.sleep(random.randint(8, 15))
continue
posts = parse_posts(data)
after = data.get("data", {}).get("after") # Update pagination cursor
if not posts:
print(" No posts retrieved, possibly reached last page\n")
break
all_posts.extend(posts)
print(f" Retrieved {len(posts)} this round, total {len(all_posts)}")
for p in posts:
print(f" [{p['score']:>6} pts] {p['title'][:60]}")
print()
# Simulate real user behavior with random delay
if i < ROUNDS - 1:
sleep_time = random.randint(6, 12)
print(f" Waiting {sleep_time} seconds before continuing...\n")
time.sleep(sleep_time)
print(f"\nScraping complete. Retrieved {len(all_posts)} posts in total.")
return all_posts
if __name__ == "__main__":
main()
2. Tips to Improve Scraping Stability
Besides using rotating proxy, the following best practices can improve stability:
Request interval and randomness
Avoid fixed request frequency and introduce random delays such as time.sleep(random.uniform(5,15)). Session rotation in IPFoxy Proxies can help simulate real user behavior and reduce high-frequency requests.
User-Agent rotation
Use multiple User-Agent strings as shown in the example.
Handle CAPTCHA and redirects
Manual intervention or third-party services may be required when CAPTCHA appears.
Exception handling
Handle network latency, proxy failures, and structure changes properly.
Data storage
Save scraped data promptly to prevent data loss.
Follow robots.txt
Check https://www.reddit.com/robots.txt before scraping.
Respect target website
Control scraping frequency and avoid excessive pressure. For large-scale scraping, consider using Reddit official API.
IV. FAQ
Rotating residential proxy is recommended because it provides better stability, lower block risk, and more realistic user network behavior.
Avoid high-frequency requests, add request intervals, rotate User-Agent, and simulate real user behavior while using rotating residential proxy.
3. Is scraping Reddit data legal?
Generally, scraping publicly accessible data without login requirements is acceptable, such as public posts, comments, and engagement metrics
V. Summary
By combining Python scraping logic, stable request strategies, and high-quality proxy environments, you can significantly improve Reddit scraping success rate and stability. For large-scale or long-term data collection, using residential proxy helps reduce blocking risks and ensures data continuity, enabling a more stable and efficient Reddit data scraping solution.

