In 2026, AI application development has entered the explosive era of Agentic Workflows. For developers, APIs are no longer just simple chat interfaces—they have become the underlying engines that drive complex business logic.
Choosing the right LLM API is no longer just about model capability. You also need to evaluate cost, stability, risk control restrictions, and global availability.
This article will walk you through the mainstream LLM APIs in 2026 and, more importantly, explain how to reliably integrate and operate them in real-world production environments.
I. What is an LLM API?
An LLM API (Large Language Model API) is essentially an interface provided by major AI companies that allows developers to access powerful models without training them from scratch.
Through simple HTTP requests, developers can perform tasks such as text generation, conversation, code generation, and data analysis.
Common API capabilities include:
- Text generation (Chat / Completion)
- Embedding generation (for search / RAG)
- Multimodal capabilities (image / audio / video understanding)
- Agent execution (tool usage / function calling)
In short, LLM APIs allow developers to use AI capabilities just like cloud services.
II. Top 10 LLM APIs in 2026: Comparison & Recommendations
1. OpenAI (GPT-5 / o2 Series): The All-Around Leader
In 2026, GPT-5 remains top-tier in reasoning, instruction following, and multilingual capabilities. The o2 series further enhances code generation and mathematical reasoning, making it ideal for high-precision tasks.
- Context: 256K (up to 1M in some versions)
- Multimodal: Supports image and audio input
- Pricing: ~$2.5 / 1M input tokens, $10 / 1M output
- Best for: General chat, coding, complex reasoning, agent development
2. Anthropic (Claude 4): Alignment & Long-Context Excellence
Claude is known for safety, controllability, and long-context processing. Claude 4 supports up to 2M tokens, capable of handling extremely large documents (even entire book series).
- Context: 2M
- Multimodal: Limited (can read text from images)
- Pricing: ~$3 / 1M input, $15 / 1M output
- Best for: Long document analysis, legal/medical compliance, content moderation
3. Google (Gemini 2.5 Ultra): Native Multimodal + Ecosystem Integration
Gemini 2.5 Ultra is a truly multimodal model, supporting text, image, audio, and video natively. It excels at analyzing YouTube videos, PDFs, and cross-modal retrieval tasks.
- Context: 1M
- Multimodal: Native support (image, video, audio)
- Pricing: ~$0.5 / 1M input, $2 / 1M output
- Best for: Multimedia analysis, Google ecosystem automation, multimodal RAG
4. Meta (Llama 4 API): Open-Source Power with High Cost Efficiency
Although open-source, Llama 4 is available via official and third-party APIs (Together AI, Groq, Replicate). It offers near GPT-5 performance at a fraction of the cost.
- Context: 128K (longer with fine-tuned versions)
- Multimodal: Text-only (community variants available)
- Pricing: ~$0.2 / 1M input, $0.4 / 1M output
- Best for: Large-scale inference, cost-sensitive apps, local deployment
5. Mistral (Large 3): Europe’s Strongest Model with Privacy Focus
Mistral Large 3 offers strong reasoning and multilingual capabilities, with a key advantage in data privacy and EU compliance.
- Context: 128K
- Multimodal: Not supported
- Pricing: ~$2 / 1M input, $6 / 1M output
- Best for: GDPR-compliant applications, enterprise data processing, multilingual tasks
6. DeepSeek (V4): High Value with Strong Reasoning
DeepSeek V4 delivers near GPT-5-level performance in math, code, and logic at extremely low cost.
- Context: 1M
- Multimodal: Not supported
- Pricing: ~$0.14 / 1M input, $0.28 / 1M output
- Best for: Long document summarization, code explanation, academic processing
7. Groq (LPU Inference API): Ultra-Fast Response
Groq focuses on hardware acceleration (LPU), enabling extremely fast token generation speeds for open-source models.
- Context: Depends on base model
- Multimodal: Depends on model
- Pricing: Mixed (request + token), slightly higher but 5–10x faster
- Best for: Real-time chat, streaming output, low-latency applications
8. X.AI (Grok-3): Real-Time Data & Unique Dataset
Grok integrates real-time data from X (Twitter), making it ideal for trend tracking and social insights.
- Context: 256K
- Multimodal: Supports image input
- Pricing: Included in X Premium+, API ~$2 / 1M input
- Best for: Social monitoring, real-time queries, content generation
9. Amazon Titan (Nova Series): Deep AWS Integration
Titan Nova models integrate seamlessly with AWS services via Bedrock, making them ideal for cloud-native applications.
- Context: 256K
- Multimodal: Supported
- Pricing: ~$0.8 / 1M input, $2.5 / 1M output
- Best for: AWS-native apps, enterprise workflows, cloud-integrated systems
10. Cohere: Best Practices for Enterprise Search & RAG
Cohere focuses on RAG and semantic search, offering built-in reranking, indexing, and citation features.
- Context: 128K
- Multimodal: Not supported
- Pricing: Tiered pricing based on usage
- Best for: Enterprise knowledge bases, chatbots, document retrieval
III. Developer Guide 2026: How to Build a Stable API Environment?
Choosing the right API is only the first step. Many developers find that while everything works locally, production environments often encounter issues like API failures or connection resets under high concurrency.
1. Why Do API Calls Get Blocked?
LLM providers (especially OpenAI, Anthropic, Google) monitor request sources due to:
- Regional compliance (some models are geo-restricted)
- Abuse prevention (e.g., scraping, key theft)
- Load control (rate limiting abnormal traffic)
Key detection factors include:
(1) IP Reputation
Requests from data center IPs (AWS, Azure, DigitalOcean) are often flagged or limited due to their association with bots and automation.
(2) Abnormal Request Patterns
High-frequency or overly regular requests (e.g., every 5 seconds exactly) are easily identified as automated behavior.
(3) Data Center Fingerprints
Detection goes beyond ASN—it includes reverse DNS, routing paths, and even TCP fingerprints (JA3/JA4).
2. How to Optimize Your API Environment?
(1) Use Realistic Network Environments
Replace data center IPs with residential or mobile IPs, which have higher trust scores and lower blocking risk.
In real-world deployments, many teams optimize API calls using IPFoxy residential Proxies (ISP-assigned real IPs). These services provide:
- Real household IP pools
- Geo-targeting (US, EU, Japan, etc.)
- IP rotation & sticky sessions
This significantly reduces the risk of bans and rate limits.
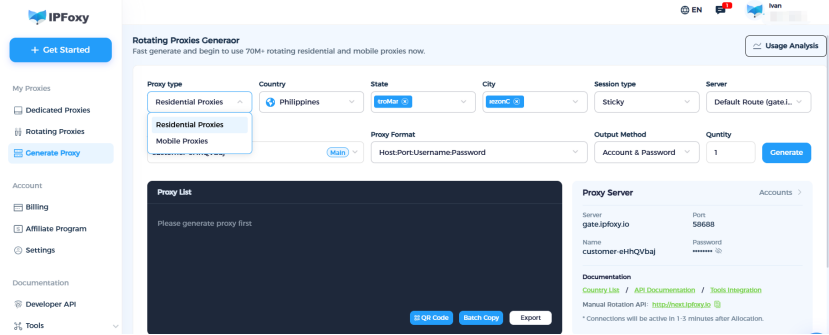
(2) Distribute Request Sources
Avoid sending all requests from a single IP. Use a proxy pool with load balancing or rotation.
(3) Reduce Automation Signals
- Add random delays (0.5–2s jitter)
- Randomize HTTP headers (User-Agent, Accept-Language)
This makes requests appear more like real user traffic.
IV. Conclusion
In 2026, AI development is not just about model performance—it’s about infrastructure reliability.
Choosing the right LLM API is only step one. Building a stable and scalable calling environment is what truly ensures business continuity.
As we move toward AGI, a robust network foundation will be the backbone of every successful AI application.

