Audio AI models rely heavily on large-scale, high-quality, and diverse audio datasets. As one of the world’s largest audio-sharing platforms, SoundCloud hosts millions of tracks along with rich metadata, making it an attractive data source for tasks such as audio analysis, generation, and enhancement.
However, due to SoundCloud’s dynamic content rendering, API limitations, and anti-scraping mechanisms, collecting data from the platform in a safe and scalable way presents significant engineering challenges.
In this complete guide, we explore the compliance considerations, technical strategies, and core challenges involved in collecting SoundCloud data, as well as how proxy-based architectures can help build stable and scalable data collection pipelines.
I. Why Use SoundCloud as a Data Source?
SoundCloud offers a wide variety of audio content, including:
Independent music, electronic tracks, podcasts, and other audio formats covering diverse styles and quality levels.
Rich metadata associated with each track, such as artist information, play counts, tags, and categories.
Community-generated playlists and classifications that help structure datasets more effectively.
Content published under Creative Commons or other open licenses, which can provide safer options for research-oriented use cases.
These characteristics make SoundCloud a strong candidate for building high-quality datasets, particularly for music generation, audio classification, and audio enhancement models.

II. Rules and Limitations to Understand Before Scraping SoundCloud
2.1 API Rate Limits
SoundCloud’s official API enforces strict rate limits. For example, requests for playable streams are capped within a 24-hour window. Once the limit is exceeded, the API returns an HTTP 429 “Too Many Requests” response.
Even when avoiding the official API and accessing the site through browser-like requests, similar rate limiting can occur—especially when a large number of pages are requested within a short period of time.
III. Compliance and Ethical Considerations
Before collecting any data, several critical factors should be evaluated:
Content usage rights: SoundCloud’s terms of service and individual creator licenses determine whether specific content can be used for AI model training. Not all content is openly licensed.
Creator rights protection: Scraping and commercializing audio data without proper authorization may infringe on creators’ rights and lead to legal disputes.
Transparency and disclosure: When using collected data for AI products or research, it is recommended to clearly disclose data sources and intended use cases.
Reviewing platform policies and applicable data usage regulations is a necessary step before starting any scraping project.
IV. Technical Challenges: Dynamic Websites and Anti-Scraping Measures
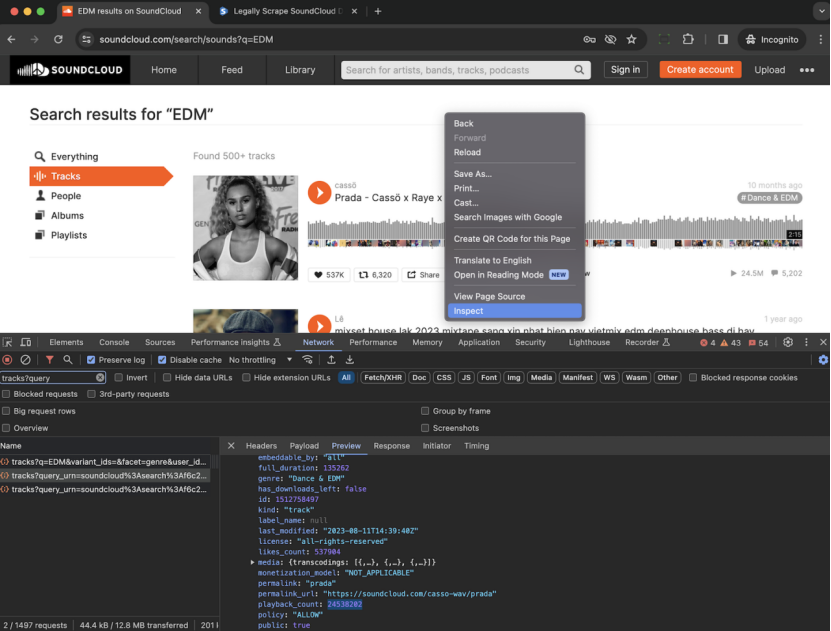
4.1 Dynamic Rendering and JavaScript Content
SoundCloud pages rely heavily on JavaScript for content rendering. Traditional HTTP requests often return incomplete or empty HTML responses. To extract meaningful data, scraping tools must simulate real browser environments or execute JavaScript.
Common approaches include:
Headless browsers such as Puppeteer, which programmatically load pages and extract data from the rendered DOM.
Web scraping API services that automatically handle JavaScript rendering and anti-bot mechanisms, returning structured data.
4.2 IP Restrictions and Risk Control
SoundCloud actively monitors abnormal request patterns. When a large number of requests originate from the same IP within a short time frame, risk control mechanisms may be triggered, resulting in:
Request blocking (HTTP 403 or 429 responses)
Temporary or permanent IP bans
To mitigate these risks, a combination of proxy rotation, session management, and request pacing is required:
Rotate IPs across a large pool of addresses
Introduce delays between requests
Apply exponential backoff retry strategies after failures
Simulate normal browsing behavior using realistic User-Agent headers, referrers, and cookies
These techniques form the foundation of a stable scraping system.
V. Building a Scalable Data Collection Strategy
Below is a general data collection framework suitable for audio AI training scenarios.
5.1 Define Target Data Fields
Before writing any code, clearly define the data fields required, such as:
Audio stream or playback URLs
Artist names and IDs
Tags, categories, and play counts
Comments and timestamps
Clear data definitions simplify downstream cleaning, labeling, and processing workflows.
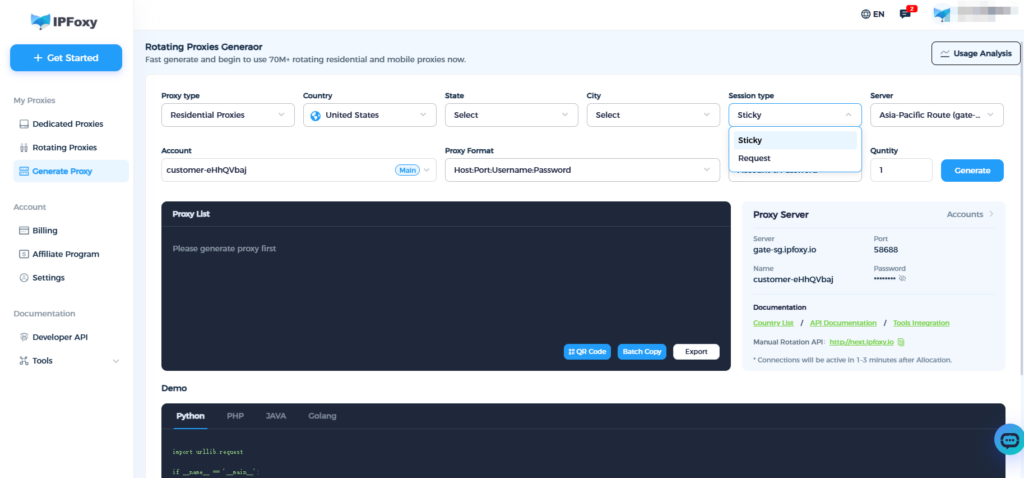
5.2 Proxy and Session Management Strategy
For large-scale scraping, rotating proxy services are recommended. For example, IPFoxy’s rotating residential proxy solutions can be easily integrated into automated scripts and have been tested under dynamic IP pool environments with the following characteristics:
- Large proxy pool with intelligent rotation, reducing IP reuse and lowering the risk of rate limiting or bans.
- Session persistence and geo-targeting support, enabling stable connections and city-level targeting when needed.
- Observability and logging through dashboards and IP logs, making it easier to diagnose failures and adjust strategies.
In practice, the following strategies can improve success rates and efficiency:
- Start with a small number of test requests to the target domain
- Automatically switch IPs or regions after repeated HTTP 403 or 429 responses
- Use sticky session IDs for the same browser session
- Limit concurrency and apply exponential backoff retry mechanisms
VI. Practical Recommendations
For most AI projects, the data collection process can be divided into three stages:
6.1 Validation Phase
Build a minimum viable pipeline and validate scraping logic and data fields using a small sample size.
6.2 Scaled Collection Phase
After validation, increase concurrency, apply more advanced proxy strategies, and store collected data in a centralized data warehouse.
6.3 Continuous Updates and Monitoring
Data collection should not be a one-time task. Continuous updates, failure rate monitoring, and automated alerts for bans or errors are essential for long-term stability.
VII. Data Cleaning and Training Preparation
Data collection is only the first step. Collected audio files and metadata must be processed before training, including:
Standardizing audio formats
Handling missing or incomplete fields
Building training labels
Applying data augmentation techniques such as noise injection or sample rate variation
These steps significantly improve the generalization performance of audio AI models.
VIII. Conclusion
Scraping SoundCloud data for audio AI model training is technically feasible, but it involves compliance, risk control, and ethical considerations. By carefully designing the data collection architecture, using reliable proxy solutions, and implementing rigorous data processing workflows, it is possible to build a high-quality and sustainable audio data pipeline.

![SocNet — digital accounts and premium subscriptions store + SMM Panel for promotion [Review, Instructions 2025]](https://www.ipfoxy.com/wp-content/uploads/2025/11/blog-ip-2-870x570.png)